









.jpg)

As V2X (vehicle-to-everything communication) becomes a global topic and the utilization of data in driving functions continues to rise, it is imperative to consider methods for detecting and filtering erroneous data more thoroughly. This topic is being researched and standardized under the designation “misbehavior detection” (abbreviated as MBD). These standards outline initial approaches for identifying erroneous data and are currently being formulated across all major regions, including Europe, China, and North America. Consequently, all pathways are available for investigation to explore various options. Studies indicate that significant outcomes can be attained through the application of artificial intelligence (AI) techniques, particularly machine learning (ML). This article presents a direct comparison between ML algorithms and traditional algorithms to either validate or challenge this assertion.

F2MD
The “Framework for Misbehavior Detection” (F2MD) serves as an open-source simulation platform for V2X interactions, allowing users to implement, test, and compare various algorithms for MBD. Within this framework, real-world traffic networks and vehicle dynamics are encapsulated in a defined scenario, which is then executed in F2MD. Communication between the vehicles is simulated. Prior to executing a scenario, users can integrate an algorithm that each vehicle will employ for processing MBD messages. Following the scenario execution, the effectiveness of the algorithm can be assessed through the analysis of collected data.
Fig. 1: Excerpt from F2MD (Paris University)
Plausibility detectors
From the outset, F2MD provides multiple options for assessing the plausibility of messages received from vehicles. To facilitate this assessment, a range of plausibility detectors is available, each yielding a value between 0 and 1 that reflects the likelihood of a message being erroneous. For instance, the speed of a vehicle is evaluated against the current maximum speed for vehicles. Utilizing these detectors, various algorithms can be developed to analyze the data and determine an overall judgment as to whether a message contains misbehavior or not.
Which algorithms are compared?
Three algorithms of this kind have already been integrated into F2MD, executing calculations in a traditional manner. One such example is an algorithm that assesses each plausibility detector against a specified threshold value. Should any of the detectors fall below this threshold, the corresponding message is categorized as misbehavior (Threshold - TH). The remaining two detectors, Aggregation (AG) and Behavioral (BH), evaluate these systems over time by conducting straightforward value comparisons and developing a behavioral score, which serves as the foundation for identifying misbehavior.
In addition to the three traditional algorithms, two machine learning-based approaches were developed and trained: a support vector machine (SVM) and a multi-layer perceptron (MLP). The former trains a hyperplane in a multidimensional space, effectively separating points of misbehavior from those exhibiting acceptable behavior. New data points are subsequently classified based on their position relative to this hyperplane. The MLP, on the other hand, is a conventional neural network that is trained and makes its decisions based on numerous mathematical computations. An attempt was also made to implement a long-short-term memory (LSTM) model; however, this approach did not yield any results due to the substantial computational resources required for F2MD.
In summary, the detection performance and computation time of five algorithms were assessed across various scenarios.
Time required and recognition performance: Results
The two diagrams presented in Figure 2 illustrate the average recognition performance, measured by accuracy, precision, recall, and F1 score, attained by the algorithms, along with the time necessary for the MBD within a message.
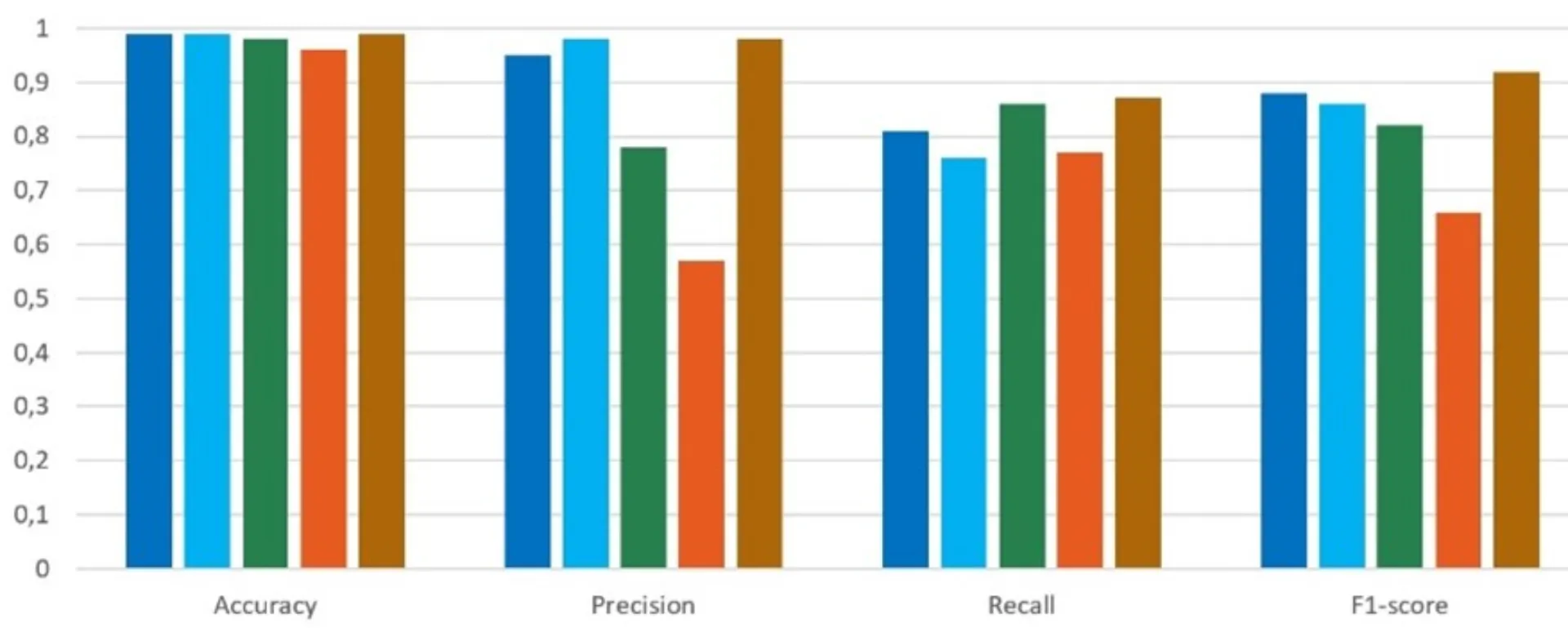
Fig. 2: Results of the comparison
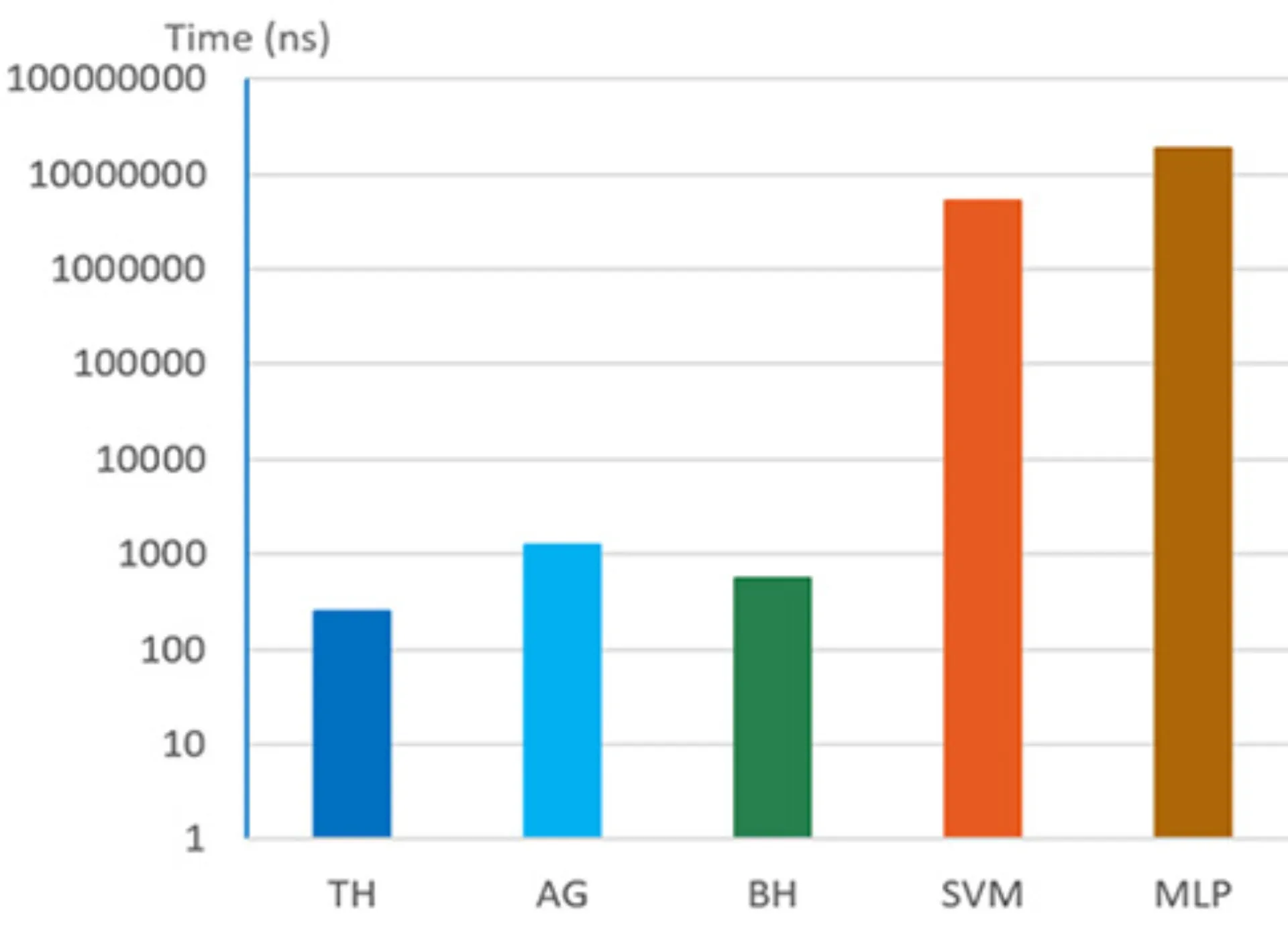

The results indicate the following:
- The MLP (brown) demonstrates the best detection performance; however, it operates at a speed that is four orders of magnitude slower than traditional algorithms.
- The TH algorithm (dark blue) demonstrated the highest efficiency regarding time.
- AG (light blue) exhibited comparable detection performance to TH; however, it operated at a speed approximately five times slower.
- BH (green) exhibited significant variability in its detection performance. In certain situations, its performance was on par with the leading algorithms, while in others, it ranked as the least effective among all.
- The SVM (orange) demonstrated to be the least effective method for detecting local misbehavior, both in terms of performance and time efficiency.
The future of V2X misbehavior detection
In conclusion, ML for the detection of misbehavior presents significant advantages over conventional algorithms in identifying a greater number of incidents. Nevertheless, certain measures must be implemented to render machine learning-based methods feasible for use in vehicles. The fundamental messages in V2X communication are transmitted every 100 milliseconds to 1 second. Given that it takes an MLP 18 milliseconds to make a decision, with 5 to 50 vehicles in the vicinity all sending messages, time could be tight.
Flexibility and proactivity at msg
The future of misbehavior detection is yet to be determined. msg is actively engaging with this topic, along with various other topics within the V2X domain, including research initiatives in China, Europe, and North America. The emphasis consistently lies on future sustainability, particularly due to the numerous uncertainties that remain in this sector, making it a vital topic for the future of the automotive industry. msg's specialists in IT security, automotive technology, and V2X will assist you in developing a system that is designed to be as adaptable as possible, ensuring readiness for future changes. Our offerings encompass a wide array of IT consulting services, concept development, the formulation of technical specifications, and the subsequent implementation of IT systems.
Do you have any questions about using AI algorithms to detect erroneous data in V2X communication?




-

- 01
- 02